
High availability (HA) refers to a system’s ability to operate without noticeable interruptions —or with minimal downtime— even in the face of hardware failures, demand spikes, or cybersecurity incidents.
To achieve this, requirements are established from the outset with a service provider through a Service Level Agreement (SLA), which defines aspects such as response/resolution times, metrics, service expectations, and uptime levels.
Given that implementing high availability requires a detailed assessment of current systems and an appropriate infrastructure, there are a number of steps that must be followed.
Step 1. Define Requirements and Service Level Agreements (SLA)
A well-written SLA (Service Level Agreement) is the contractual and operational foundation of any High Availability (HA) strategy. This document establishes metrics, responsibilities, and escalation mechanisms that align expectations between client and provider.
Key Metrics: Uptime, MTBF, MTTR
To turn an SLA into an effective metric, it’s vital to agree on quantifiable indicators:
| Metric | Definition | Why It Matters for HA |
| Uptime | Percentage of time the service remains active | 99.999% reduces downtime to ~5 min/year |
| MTBF | Mean Time Between Failures | Measures the intrinsic reliability of hardware/software |
| MTTR | Mean Time to Repair | Reflects recovery speed and process efficiency |
These metrics not only measure actual performance against what was agreed upon, but also guide: Should MTTR be further reduced for critical services? Is it necessary to improve MTBF with higher-quality hardware or added redundancy?
Uptime as a Critical Aspect to Consider Within SLA Documentation
As mentioned above, an SLA must define all the company’s availability requirements and expectations. These can be calculated using the Uptime metric, whose formula is:
Availability = (minutes in the month – downtime minutes) × 100 ÷ minutes in the month
When an SLA sets 99.9% uptime, the maximum monthly outage window is reduced to ~43 min. Just one extra tenth (99.99%) brings that down to merely 4 min. This level of granularity prevents surprises in sectors like banking or healthcare, where every offline minute costs thousands of dollars.
How to Use the SLA to Prioritize Investments
- Identify critical services and assign them aggressive uptime and fault tolerance targets.
- Compare hardware MTBF with demand forecasts; if growth threatens the target, invest before failure occurs.
- Reduce MTTR with IT automation: diagnostic scripts, runbooks, and workflows capable of executing rollbacks without human intervention.
In the end, an SLA isn’t just a piece of paper filled with numbers: it’s the living contract that guides architecture, budgeting, and support teams.
Step 2: Design Redundancy and Fault Tolerance
Without proper IT redundancy, any element —a disk, a firewall, an availability zone— becomes a single point of failure. The goal is for the infrastructure to “keep breathing” even if one or several components collapse.
Redundancy Strategies
- Hardware redundancy: include duplicate components (power supplies, servers, controllers or disks) so that, in case one fails, its counterpart takes over without interrupting the service.
- Network redundancy: deploy multiple routes and links, use devices in HA (high availability) mode, and have multiple internet circuits to eliminate single points of failure in the communications layer.
- Clustering: group servers into active/passive or active/active clusters with dedicated “heartbeat” channels. This allows state synchronization between nodes and quick switching upon detecting any failure.
Fault Tolerance Mechanisms
- Automatic failover: systems that constantly monitor the health of each node and immediately switch to the configured backup when unavailability is detected, minimizing MTTR and avoiding the need for manual intervention.
- Load balancing: distribute requests or transactions among multiple instances of the same service. If one node stops responding, the balancer redirects traffic to the rest, maintaining service continuity and optimizing resource usage.
When combined, these mechanisms bring the fault tolerance concept —as demanded by the SLA— to life. The key is to monitor the status of each component and react in milliseconds… not minutes.
You may also be interested in the following article: Nginx high availability through Keepalived – Virtual IP
Step 3: Microservices Architecture, Robust APIs, and Gateway Management
Dividing business logic into independent micro-components —the so-called microservices architecture— speeds up deployments, increases scalability, and reduces the impact surface of a failure.
In High Availability (HA) environments, it’s important to divide business logic into independent microservices and manage them through APIs to achieve scalability, flexibility, and fault tolerance. Below, we go deeper into how to leverage this approach.
Advantages of a Microservices-Based Design
- Independent deployment
Each microservice can be versioned, tested, and deployed independently without impacting the rest of the system. This reduces the risk of interruptions during updates and speeds up time-to-market. - Granular scalability
Instead of replicating an entire monolithic application, we can scale only the services that need it (for example, increasing instances of the payment service without touching the product catalog). This optimizes cloud resources and costs. - Fault isolation
If a microservice fails, it doesn’t bring down the entire platform: thanks to a distributed architecture, the rest of the ecosystem remains operational, and functionality can be gracefully degraded. - Improved maintainability
The reduced size of each service makes code easier to understand, lowers coupling, and speeds up onboarding of new developers to the project.
Resilience Patterns
To ensure a High Availability environment, it’s necessary to establish resilience patterns so that the system is prepared to respond to any operational failure, whether partial or due to load spikes.
These patterns should be built into the design. Below are some of the most important ones:
- Circuit Breaker
Monitors responses from a remote service and, after exceeding a configured error threshold (similar to an electrical circuit), “opens the circuit” to temporarily block new requests. After a wait time, it moves to half-open state and allows a test request; if it succeeds, it closes the circuit and restores normal flow; if it fails, it reopens.
This pattern protects already degraded services from additional overload and speeds up system recovery.
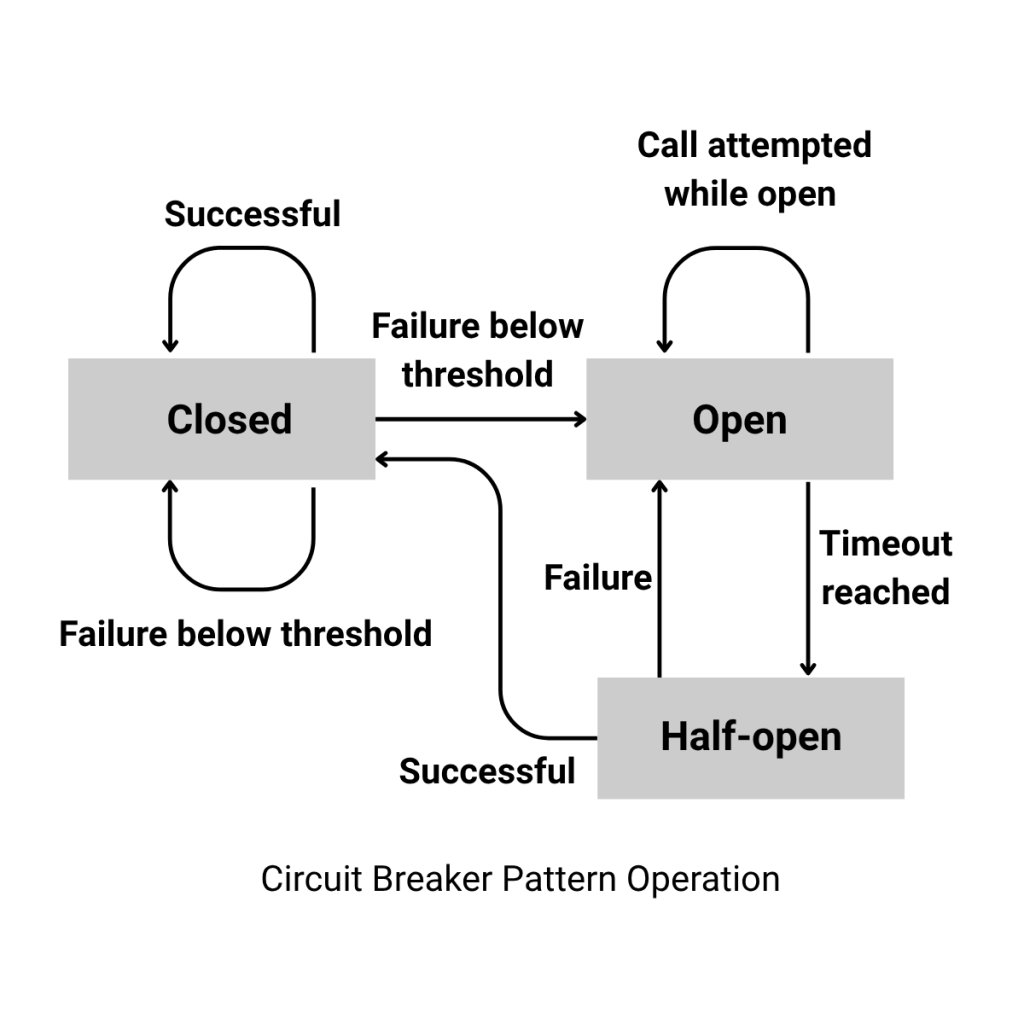
Circuit Breaker Pattern Operation
- Retry
Automatically retries failed operations a limited number of times, often using exponential back-off (and sometimes jitter) to handle transient errors (packet loss, brief network outages, or saturated services). It’s important to combine this with a circuit breaker to avoid worsening prolonged failures.
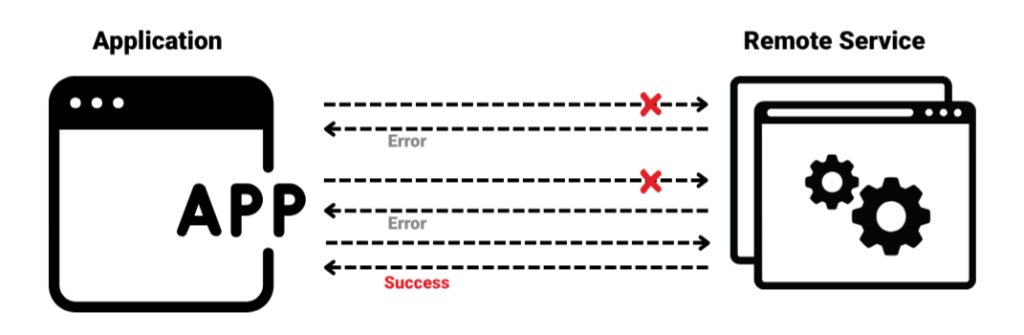
Retry Pattern
- Fallback
When all retries or the circuit breaker fail, an alternate path is invoked: it may be a default value, cached data, or a degraded version of the service. This way, some functionality is preserved without interrupting the user experience or propagating errors to other components. - Timeout
Sets a maximum wait time for each call (e.g., 2 s for an HTTP request). If exceeded, the operation is canceled and marked as failed, avoiding indefinite blocks and freeing resources.
A timeout that’s too short can generate false negatives; one that’s too long delays failure detection, so it must be tuned to each service’s expected behavior.
API Gateway and End-to-End Security
To support that choreography, you need robust APIs that define clear contracts between services and an API Gateway that centralizes security, rate limiting, and caching.
Imagine the Gateway as a hotel receptionist: it decides who gets in, where they go, with what permissions, and how much load is allowed. Without that filter, an anomalous spike or denial-of-service attack could bring down the whole building, compromising IT security and the HA objective.
Why It’s Key for High Availability
- Single entry point + load balancing
The API management layer acts as a single intermediary, distributing traffic among healthy instances and switching to another zone if one fails —eliminating the “broken telephone” between services. - Centralized security policies
OAuth 2.0/JWT authentication, TLS termination, and rate-limiting are applied before traffic touches the internal network, reducing attack surface and load on each microservice. - Versioning and canary deployments
Version-based routing (/v1, /v2) allows new features to be released without downtime, essential for meeting “five nines” SLA targets. - Unified observability
Metrics and traces in one place shorten bottleneck detection time and trigger automatic scaling before the user notices degradation.
Step 4: Implement Infrastructure as Code (IaC) and IT Automation
Using Infrastructure as Code (IaC) means writing in text files —typically YAML, HCL, or JSON— how servers, networks, and security rules should be configured. These files can be used automatically to create everything in just a few minutes.
This is vital because it allows High Availability to become not just a goal, but something that can be reproduced over and over, safely and verifiably.
Benefits of IaC for High Availability
- Absolute consistency – the same commit generates identical environments in different regions.
- Disaster recovery – cloning an entire stack in another zone takes minutes.
- Eliminates configuration drift – each deployment corrects unnoticed manual changes.
Recommended Tools
Below we show some of the most useful tools:
| Tool | Main Role | Competitive Advantage |
| Terraform | Multi-cloud provisioning | Reusable templates for Disaster Recovery (DR) |
| Ansible | System configuration | Idempotence and speed |
| Kubernetes | Container orchestration | Native self-healing and autoscaling |
Step 5: Infrastructure Monitoring and Continuous Observability
“Trust is built on seeing, not assuming.” To ensure High Availability (HA), the platform must be observed from the kernel to the business dashboard. This means infrastructure monitoring and application tracing in real time.
According to a Gartner study, the average cost of downtime is $5,600 per minute, though other estimates place it between $2,300 and $9,000 per minute. Of course, these costs vary by company size and sector.
Below, we present some key indicators and the top platforms for ensuring continuous system monitoring and immediate recovery after an incident.
The “4 Golden Signals”
To maintain continuous monitoring, four essential signals must be considered:
| Signal | What it Measures | Practical Use |
| Latency | Response time | Detect bottlenecks before they impact users |
| Traffic | Volume of requests | Correlate spikes with saturation |
| Errors | Failure ratio | Anticipate service degradation |
| Saturation | CPU, RAM, disk usage | Indicate imminent overloads |
By tracking these Four Golden Signals, you’ll cover the basic monitoring requirements for any distributed system.
Also, complement them with operational metrics like MTTD and MTTR to evaluate how effective the team is in meeting SLA targets.
Recommended Platforms
Here are some recommendations:
| Tool | Role in the HA Strategy | Highlight |
| Zabbix | Infrastructure monitoring (servers, networks, DBs) | 100% open source architecture with customizable dashboards and alerts via email, SMS, or webhooks |
| OpenSearch + Alerting | Log/metric correlation and notifications | “Monitors” programmable via UI or API; sends alerts to Slack, email, or webhook when patterns or anomalies are detected |
| Grafana Alerting | Consolidates heterogeneous sources (Prometheus, Loki, CloudWatch…) | A single rule queries several sources and triggers alerts based on compound conditions |
| OpenTelemetry (OTel) | Standard collector of traces, metrics, and logs | Second most active project in CNCF; enables apps to be instrumented once and export data to any backend |
| Metabase | Business indicator alerts | Schedule queries that trigger notifications every minute, hour, day, etc., to email, Slack, or webhooks |
These tools not only alert on impending failures; they also feed autoscaling algorithms that add nodes when demand increases —preserving fault tolerance and the High Availability (HA) promise.
Step 6: Resilience Testing and Continuous Maintenance
A High Availability (HA) infrastructure is never “finished”; it evolves alongside business requirements, cybersecurity threats, and the discovery of new bugs. That’s why resilience testing —popularized as chaos engineering— is integrated into routine operations just like any other IT automation task.
Introduction to Chaos Engineering
What is it? It’s a software discipline that deliberately injects failures (node loss, latency, network cuts…) to validate a system’s resilience before real incidents occur. Netflix popularized it in 2011 with Chaos Monkey, which randomly shuts down production instances.
These tests aim to observe how the system reacts and to identify its vulnerabilities:
Fundamental Principles of Chaos Engineering
Here are some key principles of Chaos Engineering:
| Principle | What it Means in Practice |
| Build a hypothesis around steady state | Before inducing failures, define what a “healthy” system looks like. Identify output metrics (e.g., p95 latency, throughput, error ratio) that represent its normal behavior and hypothesize they’ll remain unchanged during the experiment. |
| Vary real-world events | Introduce conditions that could actually happen: node failures, network loss, traffic spikes, faulty disks, malformed responses… The more realistic the scenario, the more valuable the learning. |
| Run experiments in production | Test environments don’t capture all real behaviors or usage patterns. For valid conclusions, failures must be injected —with appropriate precautions— on production traffic and data. |
| Automate experiments and run them continuously | Manual testing is unsustainable; automation allows repeated experiments after every change and early detection of resilience regressions by integrating chaos into the CI/CD cycle. |
| Minimize blast radius | Testing in production carries risk. Carefully limit scope (service, zone, traffic percentage) and prepare quick rollback mechanisms to keep any impact short and controlled. |
These principles —initially formulated by the Netflix team and outlined on the official Principles of Chaos site— serve as a guide to design experiments that genuinely strengthen resilience without sacrificing user experience.
Commonly Used Tools
| Tool | Type | Notable Feature |
| Gremlin | SaaS | Ready-to-use attack library and SLA reporting |
| LitmusChaos | CNCF | Kubernetes manifests + resilience dashboard |
| Chaos Mesh | OSS | Injects failures in Pod, network, disk, or kernel |
Failover Tests and Recovery Exercises
As mentioned, a key component of Chaos Engineering is scheduled drills —known as Game Days— that validate the Recovery Time Objective (RTO) and Recovery Point Objective (RPO) and train personnel without exposing them to real risk.
These exercises involve injecting failures into the system: multiple simultaneous outages are simulated to assess the environment’s resilience and measure recovery times.
Examples of simulated failures:
- Server and network link failure: simulate server crash and loss of connectivity with another component.
- Failure of two servers in an active-active cluster: assess recovery capability when two nodes fail at once.
- Server and database failure: ensure the system retains critical functions after losing both elements.
Patch Strategy and Updates Without Downtime
Now that we’ve seen how to test resilience in our environments, the next step is to establish a continuous maintenance strategy. Below is a chart comparing —at a glance— the three most common tactics for applying patches and releasing new versions without user interruption (downtime).
This allows you to quickly identify which best fits your environment depending on the type of change, deployment frequency, and service criticality.
| Technique | How It Works | When It’s Suitable |
| Blue-Green Deployment | Maintain two identical environments; the new version is tested in green and then the router is switched in seconds. Rollback is as easy as reverting to blue. | Major version jumps or schema changes. |
| Rolling Updates (Kubernetes) | Replace pods in small batches, ensuring capacity is always available; users don’t notice the change. | Microservices or any containerized app with frequent deployments. |
| Kernel Livepatch (Ksplice / Ubuntu Livepatch) | Applies critical Linux kernel patches without restarting the machine; ideal for urgent CVEs. | Servers with strict SLAs or where restarting involves complex maintenance windows. |
Combine these tactics with monthly Game Day sessions to train the team and ensure the fault tolerance promised in the SLA is real and measurable.
Step 7: IT Security and Cybersecurity as Pillars of HA
Without a clear IT security strategy, availability collapses at the first incident. Denial-of-service attacks, API manipulation, or ransomware can bring a service down in minutes.
Identity and Access Management (IAM)
Before going deeper, the following table summarizes four practices that reduce the attack surface and, with it, the likelihood of an outage due to a security breach. These ensure proper identity and access management in systems:
| Best Practice | Why It Protects Availability |
| Principle of least privilege | Limits damage if credentials are leaked or a user makes a mistake |
| Mandatory multi-factor authentication (MFA) | Prevents unauthorized access, even if the password is compromised |
| Temporary credentials / automatic rotation | Reduces the window during which a stolen key can be used |
| Separation of duties | Prevents a single person from making critical changes without review |
Encryption In Transit and At Rest
Encryption prevents attackers from reading or tampering with data and also helps avoid forced outages due to legal or regulatory incidents. Below are some protocols and encryption standards for protecting information in High Availability services.
- In transit (TLS 1.3 mandatory): AWS and other providers recommend rejecting any connection that doesn’t use at least TLS 1.2 and migrating to TLS 1.3 by default.
- At rest (AES-256): Both Google Cloud and most industry standards use AES-256 as the base algorithm for disks, databases, and objects.
- Key management: Use KMS or HSM and log each use for auditing.
API Gateway + WAF as the Perimeter
We’ve already briefly mentioned what an API Gateway is; to differentiate it from a WAF (Web Application Firewall), think of your front door: the API Gateway controls who comes in, while the WAF adds bars to protect against common attacks.
- Protection from the OWASP Top 10 threats: AWS WAF can filter SQL injection, XSS, and other attacks that exhaust resources and cause unavailability.
- Rate limiting & geoblocking: the Gateway slows traffic spikes, and the WAF blocks suspicious IP ranges, preventing overload.
IaC Scanning and Vulnerability Testing
The following table summarizes free or open-source tools that “compile” your templates to detect errors before deployment:
| Tool | What It Scans or Integrates With | Value Added |
| Checkov | Terraform, CloudFormation, Kubernetes, Docker, … | Detects misconfigurations and compliance violations before deploy |
| tfsec | Terraform | Fast static analysis with hundreds of rules and easy CI/CD integration |
| OWASP ZAP | Applications and APIs (DAST) | Leading 100% open-source web vulnerability scanner |
How to use the results: configure your pipeline so that a merge fails if any of these tools detect a critical vulnerability.
Compliance Policies (GDPR, ISO 27001…)
Standards are not bureaucracy —they are an implicit contract with your customers that demands the service remains available and the data secure.
- GDPR — Article 32 requires ensuring “the continuous availability and resilience” of systems and quick recovery after an incident.
- ISO 27001 — Annex A.17 integrates operational continuity into the security management system, aligning RTO/RPO with technical controls.
- Evidence: keep scan reports, IAM logs, and Game Day results —they prove your high availability is real and auditable.
Checklist to Put It into Action
- Review IAM permissions: apply the above table and enable MFA.
- Secure encryption: TLS 1.3 in transit, AES-256 at rest.
- Place a Gateway + WAF in front of every public API.
- Integrate Checkov/tfsec/ZAP into your pull requests.
- Store GDPR/ISO evidence: incidents, scans, and drills.
By combining strong security controls with clear legal requirements, your platform resists attacks, stays compliant, and maintains High Availability of services.
Success Stories from Chakray
A large Spanish wireless broadcasting services company, listed on the IBEX-35 and EuroStoxx 600, needed to launch Smart City projects for public administrations.
The challenge involved integrating highly diverse systems, exposing and securing APIs, and managing identities —all without expanding the internal team. In 2018, the operator hired Chakray to take charge of consulting, implementation, and operations, using the WSO2 platform.
Chakray designed a containerized cluster with WSO2 API Manager, Identity Server,, and Analytics; customized authentication (JWT) and approval flows; migrated legacy versions; and automated deployments through CI/CD.
The IT Director stated:
“Based on the experience we’ve had with Chakray, which has been completely satisfactory, and knowing they have high-level professionals in all areas of IT systems integration, we consider them an optimal option to provide consulting, implementation, development, and training services on the WSO2 platform.”
See the full Success Story here: Europe Telecom
Conclusion
High Availability isn’t a single component or a simple setting: it’s an end-to-end process that spans from defining a realistic SLA to applying patches without service interruption.
- SLA and metrics (Step 1) – The starting point: agree in writing on uptime, MTBF, and MTTR levels that everyone understands and can measure.
- Redundancy and fault tolerance (Step 2) – Eliminate single points of failure with duplicate hardware, alternate network routes, clusters, and load balancing.
- Microservices and API management (Step 3) – Break logic into small services, protect them with an API Gateway, and gain granular scalability.
- Infrastructure as code (Step 4) – Document the platform in reproducible files to deploy or recover environments in minutes.
- Monitoring and response (Step 5) – Watch the Four Golden Signals, automate alerts, and reduce MTTR with runbooks and self-healing.
- Resilience testing and continuous maintenance (Step 6) – Run Game Days, inject controlled failures, and update with blue-green, rolling, or livepatch —all without downtime.
- Security and compliance (Step 7) – Strengthen IAM, encrypt data, place a WAF in front of your APIs, and demonstrate conformity with GDPR or ISO 27001.
When these seven steps work together, you get a platform that withstands failures, scales with demand, and follows the rules —the perfect combination to protect both revenue and reputation.
Want to Take Your Availability to the Next Level?
Talk to one of our experts today and discover how to implement High Availability in your own platform —resilient and fault-tolerant.
Contact our team and request a consultation here!
Contact our team and discover the cutting-edge technologies that will empower your business.

Talk to our experts!




