
La alta disponibilidad (HA) se refiere a la capacidad de un sistema para operar sin interrupciones perceptibles —o con períodos de inactividad ínfimos—, incluso delante de fallos de hardware, picos de demanda o incidentes de ciberseguridad.
Para esto, se establecen desde un inicio los requerimientos con un proveedor de servicios, a través un acuerdo de nivel de servicio (SLA), en el que se define aspectos que incluyen: tiempos de respuesta/resolución, métricas, expectativas del servicio y tiempos de actividad.
Considerando que para la implementación de Alta Disponibilidad se requiere de una evaluación detallada de los sistemas actuales y una infraestructura adecuada, hay una serie de pasos que deben cumplirse.
Paso 1. Definir requerimientos y Acuerdos de Nivel de Servicio (SLA)
Un SLA (Service Level Agreement) bien redactado es el cimiento contractual y operativo de cualquier estrategia de Alta Disponibilidad (HA). Este documento establece métricas, responsabilidades y mecanismos de escalamiento que alinean expectativas entre cliente y proveedor.
Métricas clave: Uptime, MTBF, MTTR
Para convertir un SLA en una métrica efectiva, es de vital importancia acordar indicadores cuantificables:
| Métrica | Definición | Por qué importa para HA |
| Uptime | Porcentaje de tiempo en que el servicio permanece activo | Un 99,999 % reduce el tiempo de inactividad a ~5 min/año |
| MTBF | Tiempo medio entre fallos | Mide la confiabilidad intrínseca del hardware/software |
| MTTR | Tiempo medio de reparación | Refleja la velocidad de recuperación y la eficacia de los procesos |
Estas métricas no solo permiten medir el desempeño real frente a lo acordado, sino que también orientan: ¿conviene reducir más el MTTR para servicios críticos? ¿Es necesario mejorar el MTBF con hardware de mayor calidad o redundancia adicional?
Uptime como aspecto crítico a considerar dentro de la documentación SLA
Como mencionamos arriba, en un SLA deben definirse todos los requerimientos y expectativas de disponibilidad de la empresa, estos pueden calcularse a través de la métrica Uptime cuya fórmula es:
Disponibilidad = (minutos en el mes – minutos de inactividad) × 100 ÷ minutos en el mes
Cuando el SLA fija un uptime del 99,9 %, la ventana máxima de caída mensual se reduce a ~43 min. Una sola décima extra (99,99 %) derriba ese límite a apenas 4 min. Este nivel de granularidad evita sorpresas en sectores como banca o salud, donde cada minuto fuera de línea cuesta miles de dólares.
Cómo usar el SLA para priorizar inversiones
- Identificar servicios críticos y asignarles objetivos agresivos de uptime y tolerancia a fallos.
- Contrastar el MTBF del hardware con pronósticos de demanda; si el crecimiento compromete el objetivo, invertir antes de sufrir el fallo.
- Reducir el MTTR con automatización TI: scripts de diagnóstico, runbooks y flujos de trabajo capaces de ejecutar rollback sin intervención humana.
Al final, un SLA no es un papel lleno de números: es el contrato vivo que guía la arquitectura, el presupuesto y los equipos de soporte.
Paso 2: Diseñar redundancia y tolerancia a fallos
Sin redundancia TI adecuada cualquier elemento —un disco, un firewall, una zona de disponibilidad— se convierte en punto único de fallo. El objetivo es que la infraestructura “siga respirando” aún si uno o varios componentes colapsan.
Estrategias de redundancia
- Redundancia de hardware: incluir componentes duplicados (fuentes de alimentación, servidores, controladoras o discos) para que, en caso de fallo de uno, su homólogo tome el relevo sin interrumpir el servicio.
- Redundancia de red: desplegar rutas y enlaces múltiples, aprovechar dispositivos en modo HA (alta disponibilidad) y contar con múltiples circuitos de Internet para eliminar puntos únicos de fallo en la capa de comunicaciones.
- Clustering: agrupar servidores en clústeres activos/pasivos o activos/activos con canales de “heartbeat” dedicados. Esto permite sincronizar estado entre nodos y realizar conmutaciones rápidas ante cualquier fallo detectado.
Mecanismos de tolerancia a fallos
- Failover automático: sistemas que monitorizan constantemente la salud de cada nodo y conmutan de forma inmediata al respaldo configurado cuando detectan indisponibilidad, minimizando el MTTR y evitando la necesidad de intervención manual.
- Balanceo de carga: distribuir peticiones o transacciones entre varias instancias de un mismo servicio. Si un nodo deja de responder, el balanceador redirige el tráfico al resto, manteniendo la continuidad del servicio y optimizando el aprovechamiento de recursos.
Cuando se combinan, estos mecanismos materializan el concepto de tolerancia a fallos que el SLA demanda. La clave es monitorear el estado de cada componente y reaccionar en milisegundos… no en minutos.
El siguiente Artículo puede interesarte: Alta disponibilidad en Nginx mediante Keepalived – IP Virtual
Paso 3: Arquitectura de microservicios, APIs robustas y gestión de Gateway
Dividir la lógica de negocio en micro‑componentes independientes —la llamada arquitectura de microservicios— agiliza despliegues, incrementa la escalabilidad y reduce la superficie de impacto de un fallo.
En entornos de Alta Disponibilidad (HA), es importante dividir la lógica de negocio en microservicios independientes y gestionarlos a través de APIs para lograr escalabilidad, flexibilidad y tolerancia a fallos. A continuación, profundizamos en cómo aprovechar este enfoque.
Ventajas de un diseño basado en microservicios
- Despliegue independiente
Cada microservicio puede versionarse, testearse y desplegarse de forma autónoma sin impactar al resto del sistema. Esto reduce el riesgo de interrupciones durante actualizaciones y acelera él time-to-market. - Escalabilidad granular
En lugar de replicar toda una aplicación monolítica, podemos escalar solo aquellos servicios que lo requieran (por ejemplo, aumentando instancias del servicio de pagos sin tocar el catálogo de productos). Esto optimiza recursos y costes en la nube. - Aislamiento de fallos
Si un microservicio presenta un fallo, este no provoca la caída de toda la plataforma: gracias a una arquitectura distribuida, el resto del ecosistema sigue operativo, y podemos degradar funcionalidades de forma controlada.
- Mejora de la mantenibilidad
El tamaño reducido de cada servicio facilita la comprensión del código, reduce el acoplamiento y acelera la incorporación de nuevos desarrolladores al proyecto.
Patrones de resiliencia
Para garantizar un entorno de Alta disponibilidad, es necesario establecer patrones de resiliencia, de modo que nuestro sistema este preparado para responder ante cualquier fallo operativo, ya sean parciales o picos de carga.
Estos patrones deben establecerse desde el diseño, a continuación mostraremos algunos de los más importantes:
Circuit Breaker
Monitorea las respuestas de un servicio remoto y, al superar un umbral de errores configurado, (similar a un circuito eléctrico) “abre el circuito” para bloquear temporalmente nuevas peticiones. Tras un tiempo de espera, pasa a estado medio-abierto y permite una petición de prueba; si tiene éxito, cierra el circuito y restaura el flujo normal, y si falla vuelve a abrirse.
Este patrón protege a los servicios ya degradados de una sobrecarga adicional y acelera la recuperación del sistema.
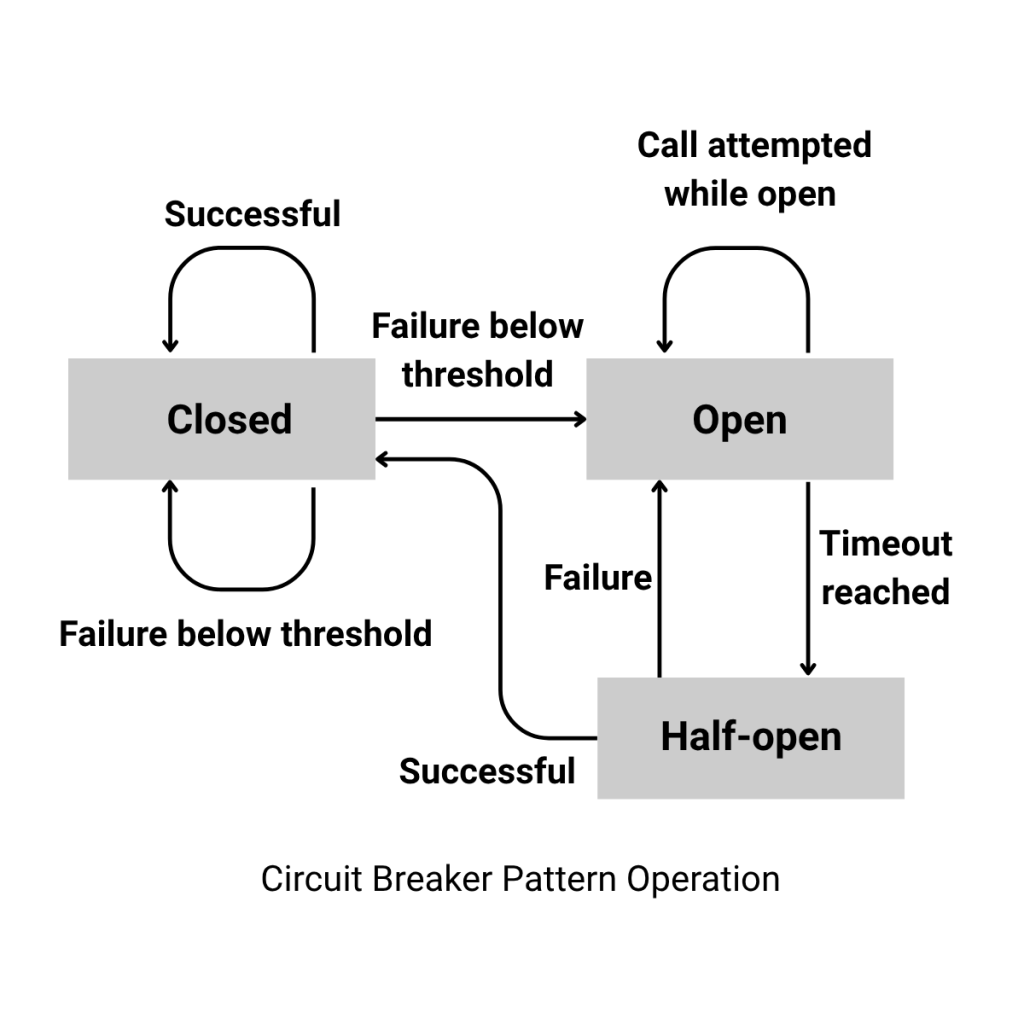
Circuit Breaker Pattern Operation
Retry
Reintenta automáticamente operaciones fallidas un número limitado de veces, habitualmente con back-off exponencial (y a veces jitter) para manejar errores transitorios (pérdida de paquetes, breves caídas de red o servicios saturados). Es importante combinarlo con un circuit breaker para no agravar fallos prolongados.
Retry Pattern
Fallback
Cuando todos los reintentos o el circuit breaker han fallado, se invoca una ruta alternativa: puede ser un valor por defecto, datos en caché o una versión degradada del servicio. Así se mantiene cierta funcionalidad sin interrumpir la experiencia de usuario ni propagar errores a otros componentes.
Timeout
Establece un límite máximo de espera para cada llamada (por ejemplo, 2 s para una petición HTTP). Si se supera, la operación se cancela y se marca como fallida, evitando bloqueos indefinidos y liberando recursos. Un timeout demasiado corto puede generar falsos negativos; uno muy largo retrasa la detección de fallos, por lo que hay que ajustarlo según el comportamiento esperado de cada servicio.
API Gateway y seguridad de extremo a extremo
Para sostener esa coreografía necesitas APIs robustas que definan contratos claros entre servicios y un API Gateway que centralice seguridad, rate limiting y caching.
Imagina el Gateway como un recepcionista de hotel: decide quién pasa, a dónde, con qué permisos y cuánta carga acepta. Sin ese filtro, un pico anómalo o un ataque de denegación de servicio podría derribar todo el edificio, comprometiendo la seguridad TI y el objetivo de HA.
Por qué es clave para la Alta Disponibilidad
- Punto de entrada único + balanceo
La capa de gestión API gateway actúa como un intermediario único, que reparte el tráfico entre instancias sanas y conmuta a otra zona si una falla, eliminando el “teléfono descompuesto” entre servicios.
- Políticas de seguridad centralizadas
Autenticación OAuth 2.0/JWT, terminación TLS y rate-limiting se aplican antes de que el tráfico toque la red interna, reduciendo la superficie de ataque y la carga en cada microservicio.
- Versionado y despliegues canary
El enrutado por versión (/v1, /v2) permite desplegar nuevas funciones sin cortes, indispensable para alcanzar SLA de “cinco nueves”.
- Observabilidad unificada
Métricas y trazas en un solo lugar acortan el tiempo de detección de cuellos de botella y disparan escalados automáticos antes de que el usuario note la degradación.
Paso 4: Implementar Infraestructura como Código (IaC) y Automatización TI
Usar Infraestructura como Código (IaC) es escribir en archivos de texto —generalmente YAML, HCL o JSON— cómo deben configurarse los servidores, redes y reglas de seguridad. Esos archivos se pueden usar automáticamente para crear todo en pocos minutos.
Esto es vital, porque permite que la Alta Disponibilidad no sea solo un objetivo y en su lugar se convierta en algo que se puede reproducir una y otra vez, de forma segura y comprobable.
Beneficios de IaC para Alta Disponibilidad
- Coherencia absoluta – el mismo commit genera entornos idénticos en distintas regiones.
- Recuperación ante desastres – clonar un stack completo en otra zona lleva minutos.
- Elimina la deriva de configuración – cada despliegue corrige cambios manuales inadvertidos.
Herramientas recomendadas
A continuación mostramos algunas de las herramientas más útiles:
| Herramienta | Rol principal | Ventaja competitiva |
| Terraform | Provisión multi‑cloud | Plantillas reutilizables para Disaster Recovery (DR) |
| Ansible | Configuración de sistemas | Idempotencia y velocidad |
| Kubernetes | Orquestación de contenedores | Self‑healing y autoscaling nativos |
Paso 5: Monitoreo de infraestructura y observabilidad continua
“La confianza se basa en ver, no en suponer.” Para garantizar la Alta Disponibilidad (HA) hay que observar la plataforma desde el kernel hasta el dashboard de negocio. Eso implica monitoreo de infraestructura y tracing de aplicaciones en tiempo real.
Según un estudio de Gartner, el costo promedio del tiempo de inactividad es de $5,600 dólares por minuto, aunque otras estimaciones lo sitúan entre $2,300 y $9,000 dólares. Cabe aclarar que estos costos varían según el tamaño de la empresa y el sector al que pertenece.
A continuación, presentamos algunos indicadores clave y las plataformas mejor posicionadas para garantizar el monitoreo continuo de sistemas y la recuperación inmediata tras un incidente.
Las “4 señales doradas”
Para mantener un monitoreo continuo, deben tomarse en cuenta cuatro señales esenciales:
| Señal | ¿Qué mide? | Uso práctico |
| Latencia | Tiempo de respuesta | Detecta cuellos antes de que afecten |
| Tráfico | Volumen de peticiones | Correlaciona picos con saturación |
| Errores | Ratio de fallos | Anticipa degradaciones de servicio |
| Saturación | Uso de CPU, RAM, disco | Señala sobrecargas inminentes |
Si tomas en cuenta estas Cuatro Señales Doradas, cubrirás los requisitos básicos de monitoreo en cualquier sistema distribuido.
Asimismo, complementa con métricas operativas como MTTD y MTTR para evaluar la eficacia del equipo frente a los objetivos del SLA.
Plataformas recomendadas
A continuación mostramos algunas recomendaciones:
| Herramienta | Rol en la estrategia HA | Destacado |
| Zabbix | Monitoreo de infraestructura (servidores, redes, BBDD) | Arquitectura 100 % open source con dashboards personalizables y alertas por e-mail, SMS o webhooks |
| OpenSearch + Alerting | Correlación de logs/métricas y notificaciones | “Monitors” programables desde UI o API; envía avisos a Slack, correo o webhook ante patrones o anomalías |
| Grafana Alerting | Consolida fuentes heterogéneas (Prometheus, Loki, CloudWatch…) | Una misma regla consulta varios orígenes y lanza alertas según condiciones compuestas |
| OpenTelemetry (OTel) | Recolector estándar de trazas, métricas y logs | Segundo proyecto más activo de la CNCF, facilita instrumentar apps una sola vez y exportar datos al backend elegido |
| Metabase | Alertas sobre indicadores de negocio | Programa consultas que disparan notificaciones por minuto, hora, día, etc., hacia e-mail, Slack o webhooks |
Estas herramientas no solo alertan de fallos inminentes; también alimentan algoritmos de autoscaling que añaden nodos cuando la demanda crece, preservando la tolerancia a fallos y la promesa de Alta Disponibilidad (HA).
Paso 6: Pruebas de resiliencia y mantenimiento continuo
La infraestructura de Alta Disponibilidad (HA) nunca está “terminada”; evoluciona al ritmo de los requisitos de negocio, las amenazas de ciberseguridad y la aparición de nuevos bugs. Por eso, las pruebas de resiliencia —popularizadas como chaos engineering— se integran en la rutina operativa igual que cualquier otra tarea de automatización TI.
Introducción al chaos engineering
¿Qué es? Se trata de una disciplina de software que inyecta fallos deliberados (pérdida de nodo, latencia, corte de red…) para validar la resiliencia de un sistema antes de que ocurran incidentes reales. Netflix la popularizó en 2011 con Chaos Monkey, que apaga instancias al azar en producción.
Con estas pruebas se busca observar la reacción del sistema e identificar sus vulnerabilidades:
Principios fundamentales del Chaos Engineering
A continuación describiremos algunos de los principios clave del Chaos Engineering:
| Principio | ¿Qué significa en la práctica? |
| Construye una hipótesis sobre el estado estable | Antes de provocar fallos hay que saber qué aspecto tiene un sistema “sano”. Define métricas de salida (p. ej., latencia p95, throughput, ratio de errores) que representen su comportamiento normal y formula la hipótesis de que se mantendrán inalteradas durante el experimento. |
| Varía eventos del mundo real | Introduce condiciones que realmente puedan ocurrir: caída de nodos, pérdida de red, picos de tráfico, discos defectuosos, respuestas mal formadas… Cuanto más fiel sea el escenario a la realidad, más valioso será el aprendizaje. |
| Ejecuta los experimentos en producción | Los entornos de prueba no capturan todo el comportamiento ni los patrones de uso reales. Para obtener conclusiones válidas, las inyecciones de fallo deben hacerse —con las debidas precauciones— sobre tráfico y datos de producción. |
| Automatiza los experimentos y ejecútalos de forma continua | Ejecutar pruebas manuales es insostenible; la automatización permite repetir experimentos tras cada cambio y detectar regresiones de resiliencia de manera temprana, integrando el caos en el ciclo CI/CD. |
| Minimiza el radio de impacto | Al experimentar en producción existe riesgo para los usuarios. Limita cuidadosamente el alcance (servicio, zona, porcentaje de tráfico) y prepara mecanismos de cancelación rápida para que cualquier impacto sea corto y controlado. |
Estos principios —formulados inicialmente por el equipo de Netflix y recogidos en el sitio oficial Principles of Chaos— sirven como guía para diseñar experimentos que verdaderamente fortalezcan la resiliencia sin sacrificar la experiencia del usuario.
Algunas de las herramientas más habituales usadas son:
| Herramienta | Tipo | Particularidad destacada |
| Gremlin | SaaS | Biblioteca de ataques listos para usar y reporte de SLA |
| LitmusChaos | CNCF | Manifiestos Kubernetes + panel de resiliencia |
| Chaos Mesh | OSS | Inyecta fallos en Pod, red, disco o kernel |
Pruebas de failover y ejercicios de recuperación
Como mencionamos, un componente esencial del Chaos Engineering, son los simulacros programados —conocidos como Game Days— validan el objetivo de tiempo de recuperación (RTO) y el objetivo de punto de recuperación (RPO), y entrenan al personal sin exponerlo a riesgos reales.
Estos ejercicios incluyen la inyección de fallos en el sistema: se simulan múltiples interrupciones simultáneas para evaluar la resiliencia del entorno y medir los tiempos de recuperación.
Algunos ejemplos de fallos simulados:
- Fallo de servidor y de enlace de red: simular la caída de un servidor y la pérdida de conectividad con otro componente.
- Fallo de dos servidores en un clúster activo-activo: evaluar la capacidad de recuperación cuando dos nodos fallen a la vez.
- Fallo de servidor y de base de datos: comprobar que el sistema mantiene las funciones críticas tras la pérdida de ambos elementos.
Estrategia de parches y actualizaciones sin downtime
Ahora que hemos contemplado cómo testear la resiliencia de nuestros entornos, el siguiente paso es establecer una estrategia de mantenimiento continuo, a continuación presentamos un cuadro que compara —de un vistazo— las tres tácticas más usadas para aplicar parches y lanzar nuevas versiones sin interrumpir al usuario (downtime).
Así podrás identificar rápidamente cuál se adapta mejor a tu entorno según el tipo de cambio, la frecuencia de despliegue y el nivel de criticidad del servicio.
| Técnica | Cómo funciona | Cuándo conviene |
| Blue-Green Deployment | Mantienes dos entornos idénticos; el nuevo se prueba en green y luego se conmuta el router en segundos. El rollback es tan fácil como volver a blue. | Saltos de versión mayores o cambios de esquema. |
| Rolling Updates (Kubernetes) | Sustituye pods en pequeños lotes, garantizando que siempre queda capacidad disponible; los usuarios no notan el cambio. | Microservicios o cualquier app contenedorizada que se despliegue muy a menudo. |
| Livepatch del kernel (Ksplice / Ubuntu Livepatch) | Aplica parches críticos al núcleo de Linux sin reiniciar la máquina; ideal para CVE urgentes. | Servidores con SLA estrictos o donde reiniciar implica una ventana de mantenimiento compleja. |
Combina estas tácticas con sesiones mensuales de Game Day para entrenar al equipo y garantizar que la tolerancia a fallos prometida en el SLA sea real y medible.
Paso 7: Seguridad TI y Ciberseguridad como pilares de la HA
Sin una estrategia clara de seguridad TI, la disponibilidad se quiebra al primer incidente. Los ciberataques de denegación, la manipulación de APIs o un ransomware pueden tumbar un servicio en minutos.
Gestión de identidades y accesos (IAM)
Antes de profundizar, la siguiente tabla condensa cuatro prácticas que reducen la superficie de ataque y, con ello, la probabilidad de una caída por brecha de seguridad. Estas garantizan una gestión adecuada de identidades y accesos en los sistemas:
| Buena práctica | ¿Por qué protege la disponibilidad? |
| Principio de mínimo privilegio | Limita el daño si una credencial se filtra o un usuario comete un error |
| Autenticación multifactor (MFA) obligatoria | Evita accesos no autorizados, incluso si la contraseña se compromete |
| Credenciales temporales / rotación automática | Reduce la ventana en la que una clave robada puede usarse |
| Segregación de funciones | Impide que una sola persona haga cambios críticos sin revisión |
Cifrado en tránsito y en reposo
El cifrado evita que un atacante lea o manipule datos y, al mismo tiempo, previene paradas forzadas por incidentes legales o regulatorios. A continuación mostraremos algúnos protocolos y estándares de cifrado para proteger la información en servicios de Alta Disponibilidad.
- En tránsito (TLS 1.3 obligatorio): AWS y otros proveedores recomiendan rechazar toda conexión que no use al menos TLS 1.2 y migrar a TLS 1.3 por defecto.
- En reposo (AES-256): tanto Google Cloud como la mayoría de estándares sectoriales emplean AES-256 como algoritmo base para discos, bases y objetos.
- Gestión de llaves: usa KMS o HSM y registra cada uso para auditoría.
API Gateway + WAF como perímetro
Ya hemos mencionado brevemente qué es un API Gateway; para diferenciarlo de un WAF, piensa en la puerta de tu casa: el API Gateway controla quién entra, mientras que el WAF coloca rejas para protegerte de ataques comunes.
- Protección frente a las 10 amenazas más comunes (OWASP Top 10): AWS WAF puede filtrar inyecciones SQL, XSS y otros ataques que agotan recursos y causan indisponibilidad
- Rate limiting & geobloqueo: el Gateway desacelera picos de tráfico y el WAF bloquea rangos IP sospechosos, evitando sobrecarga.
Escaneo de IaC y pruebas de vulnerabilidades
El cuadro siguiente resume las herramientas gratuitas o de código abierto que “compilan” tus plantillas buscando errores antes de desplegarlos:
| Herramienta | ¿Qué revisa o con que plataformas se comunica? | Valor añadido |
|---|---|---|
| Checkov | Terraform, CloudFormation, Kubernetes, Docker, … | Detecta configuraciones incorrectas y violaciones de cumplimiento antes del deploy |
| tfsec | Terraform | Análisis estático rápido con cientos de reglas y fácil integración CI/CD |
| OWASP ZAP | Aplicaciones y APIs (DAST) | Escáner de vulnerabilidades web líder, 100% open-source |
Cómo usar el resultado: configura tu pipeline para que un merge falle si cualquiera de estas herramientas detecta una vulnerabilidad crítica.
Políticas de cumplimiento (GDPR, ISO 27001…)
Las normas no son burocracia, son un contrato implícito con tus clientes que exige que el servicio esté disponible y los datos seguros.
- GDPR — Artículo 32 obliga a garantizar “la disponibilidad y resiliencia continuas” y la rápida restauración tras un incidente.
- ISO 27001 — Anexo A.17 integra la continuidad operativa dentro del sistema de gestión de seguridad, alineando RTO/RPO con controles técnicos.
- Evidencias: conserva reportes de escaneo, registros IAM y resultados de Game Days; son la prueba de que la alta disponibilidad es real y auditada.
Checklist para ponerlo en marcha
- Revisa permisos IAM: aplica la tabla anterior y activa MFA.
- Asegura el cifrado: TLS 1.3 en tránsito, AES-256 en reposo.
- Sitúa un Gateway + WAF delante de cada API pública.
- Integra Checkov/tfsec/ZAP en tus pull requests.
- Guarda evidencias GDPR/ISO: incidentes, escaneos y simulacros.
Al combinar controles de seguridad sólidos con requisitos legales claros, tu plataforma resiste ataques, cumple la ley y mantiene la Alta Disponibilidad de servicios.
Casos de éxito de Chakray
Una gran compañía española de servicios de radiodifusión inalámbrica, cotizante del IBEX-35 y EuroStoxx 600, debía lanzar proyectos Smart City para administraciones públicas.
El reto implicaba integrar sistemas muy dispares, exponer y segurizar APIs, y gestionar identidades, todo sin ampliar plantilla propia. En 2018 el operador contrató a Chakray para hacerse cargo de la consultoría, la implantación y la operación, para esto se usó la plataforma WSO2
Chakray diseñó un clúster contenedorizado con WSO2 API Manager, Identity Server, y Analytics, personalizó autenticación (JWT) y flujos de aprobación, migró versiones heredadas y automatizó los despliegues mediante CI/CD.
El director de TI destacó:
“Tomando en cuenta la experiencia que hemos tenido con Chakray, la cual ha sido completamente satisfactoria, y contando con profesionales de alto nivel en todos los ámbitos de integración de sistemas IT, consideramos que es una opción óptima para proveer los servicios referentes a consultoría, implantación, desarrollo y formación en la plataforma WSO2”
Ve el Caso de Éxito completo a continuación: Telecomunicaciones en Europa
Conclusión
La Alta Disponibilidad no es un único componente ni una simple configuración: es un proceso integral que abarca desde la definición de un SLA realista hasta la aplicación de parches sin detener el servicio.
- SLA y métricas (Paso 1) – El punto de partida: acordar por escrito niveles de uptime, MTBF y MTTR que todo el mundo entienda y pueda medir.
- Redundancia y tolerancia a fallos (Paso 2) – Elimina puntos únicos de fallo con hardware duplicado, rutas de red alternativas, clústeres y balanceo de carga.
- Microservicios y gestión de APIs (Paso 3) – Divide la lógica en servicios pequeños, protégelos con un API Gateway y gana escalabilidad granular.
- Infraestructura como código (Paso 4) – Documenta la plataforma en archivos reproducibles para desplegar o recuperar entornos en minutos.
- Monitoreo y respuesta (Paso 5) – Vigila las Cuatro Señales Doradas, automatiza alertas y acorta el MTTR con runbooks y autosanación.
- Pruebas de resiliencia y mantenimiento continuo (Paso 6) – Practica Game Days, inyecta fallos controlados y actualiza con blue-green, rolling o livepatch sin downtime.
- Seguridad y cumplimiento (Paso 7) – Refuerza IAM, cifra datos, coloca un WAF frente a tus APIs y demuestra conformidad con GDPR o ISO 27001.
Cuando estos siete pasos trabajan juntos, obtienes una plataforma que soporta fallos, escala con la demanda y sigue las reglas del juego: la combinación perfecta para proteger ingresos y reputación.
¿Quieres llevar tu disponibilidad al siguiente nivel?
Habla hoy mismo con uno de nuestros expertos y descubre cómo implementar una Alta Disponibilidad en tu propia plataforma, resiliente y a prueba de fallos.
¡Contacta con nuestro equipo y solicita una consultoría aquí!
Contacta con nuestro equipo y descubre las tecnologías de vanguardia que potenciarán tu negocio.

¡Habla con nuestros expertos!





