En este artículo explicaremos qué es HL7, así como también qué es HL7 FHIR para el intercambio de información clínica e integración con Red Hat Fuse y Apache Camel.
Seguiremos el siguiente índice:
|
1. ¿Qué es HL7?
Health Level Seven International (HL7) es una organización sin ánimo de lucro fundada en 1987 con el objetivo de desarrollar un framework completo de estándares para el intercambio, integración, compartición y obtención de información clínica en formato electrónico para su uso en la práctica clínica y en la gestión, provisión y evaluación de servicios de salud. Forman parte de esta organización más de 1600 miembros en más de 50 países, representando a proveedores de servicios de salud, gobiernos, aseguradoras, compañías farmacéuticas, fabricantes y firmas de consultoría.
Su objetivo es el de facilitar la interoperabilidad de datos clínicos a nivel global.
2. ¿Qué es HL7 FHIR?
HL7 Fast Healthcare Interoperability Resources (FHIR) es un estándar de interoperabilidad para facilitar el intercambio de información clínica entre proveedores de servicios de salud, pacientes, cuidadores, aseguradoras, investigadores, y cualquier otra parte implicada en el ecosistema de salud.
FHIR define dos aspectos:
-
Un modelo de datos de recursos de salud
-
Una API para el intercambio de información
2.1 Evolución de FHIR
FHIR es la evolución de varios estándares producidos por la organización HL7 a lo largo de décadas, partiendo de versiones anteriores como HL7 version 2.x and HL7 version 3.x. Desde 2011 se han ido publicando distintas propuestas, siendo la Release 4 la última versión estable.
-
Octubre 2019: FHIR R4, Primera versión normativa
-
Marzo 2017: FHIR R3, Standards for Trial Use (STU)
-
Octubre 2015: FHIR R2 DSTU, Draft Standard for Trial Use (DSTU) (borrador)
-
Febrero 2014: FHIR R1 DSTU, Draft Standard for Trial Use (DSTU) (borrador)
-
Agosto 2011: Resources For Healthcare (RFH) (borrador inicial)
2.2 Ventajas de HL7 FHIR
Las principales ventajas de utilizar FHIR son las siguientes:
-
Permite facilitar la interoperabilidad entre sistemas heterogéneos, desde sistemas legacy, a múltiples tipos de dispositivos como ordenadores, tablets, smartphones, dispositivos médicos, etc, así como entre distintas aplicaciones, y facilita la integración de nuevas aplicaciones medicas con sistemas existentes.
-
Constituye una alternativa a sistemas basados en documentos, permitiendo un mayor grado de detalle al poder exponer elementos como servicios. Por ejemplo elementos básicos como pacientes, ingresos, análisis, diagnósticos, medicaciones, pueden ser consultados y manipulados individualmente a través de su propia URL.
-
La estandarización y granularidad del modelo de datos permite agilizar su procesado automático, sin tener que recurrir a técnicas de transformación o preprocesado.
-
Es fácilmente integrable con aplicaciones actuales al estar su API basada en tecnologías REST.
-
Existen implementaciones open source para distintos lenguajes como Java, .NET, Ruby, Python, Delphi, Swift, PHP, …
3. Casos de uso de HL7 FHIR
El intercambio de información clínica entre distintas partes pueden dar lugar a casos de uso tales como por ejemplo:
-
Alerta de interacción de medicamentos: El sistema puede alertar cuando se prescriben a la vez medicamentos que pueden interaccionar entre sí de manera negativa para la salud del paciente.
-
Reducción de tiempos de espera: El análisis de datos de asistencia a urgencias e ingresos hospitalarios pueden permitir un mejor dimensionado y optimización de los recursos para reducir tiempos de espera.
-
Seguimiento epidemiológico: Los hospitales pueden publicar las estadísticas de infecciones de sus pacientes para que puedan explotarlos investigadores y agencias de salud pública.
-
Telemedicina: Transmisión de dispositivos de medición (tensiómetros, termómetros, glucómetros, espirómetros,…) desde el domicilio del paciente al servicio de salud para su monitorización y análisis.
4. Modelo de datos HL7 FHIR
El dato fundamental en FHIR es el denominado recurso. Ejemplos de recursos pueden ser: ingreso, paciente, historial, medicación, plan de rehabilitación, alta,…
Podemos definir un recurso como una entidad que:
-
Tiene una identidad única (ubicación URL) asignada en el servidor.
-
Pertenece a un tipo de recurso entre los definidos por la especificación FHIR.
-
Contiene un conjunto de datos estructurados, en función del tipo de recurso.
-
Tiene una versión que cambia si se modifica el contenido del recurso.
Cada recurso se compone de una estructura de datos que pueden ser tipos primitivos o complejos, o referencias a otros recursos.
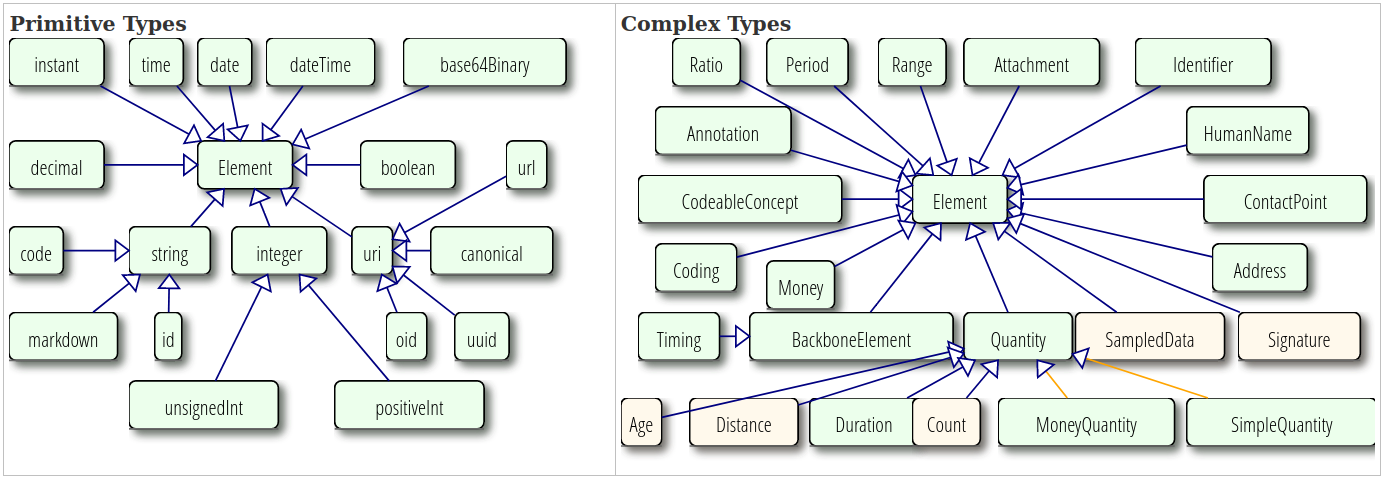
Fuente: FHIR v4.0.1 Datatypes Definitions
En el siguiente diagrama vemos el ejemplo de un recurso paciente, que se compone de un identificador, fecha de nacimiento, estado civil, personas de contacto, médico, etcétera.
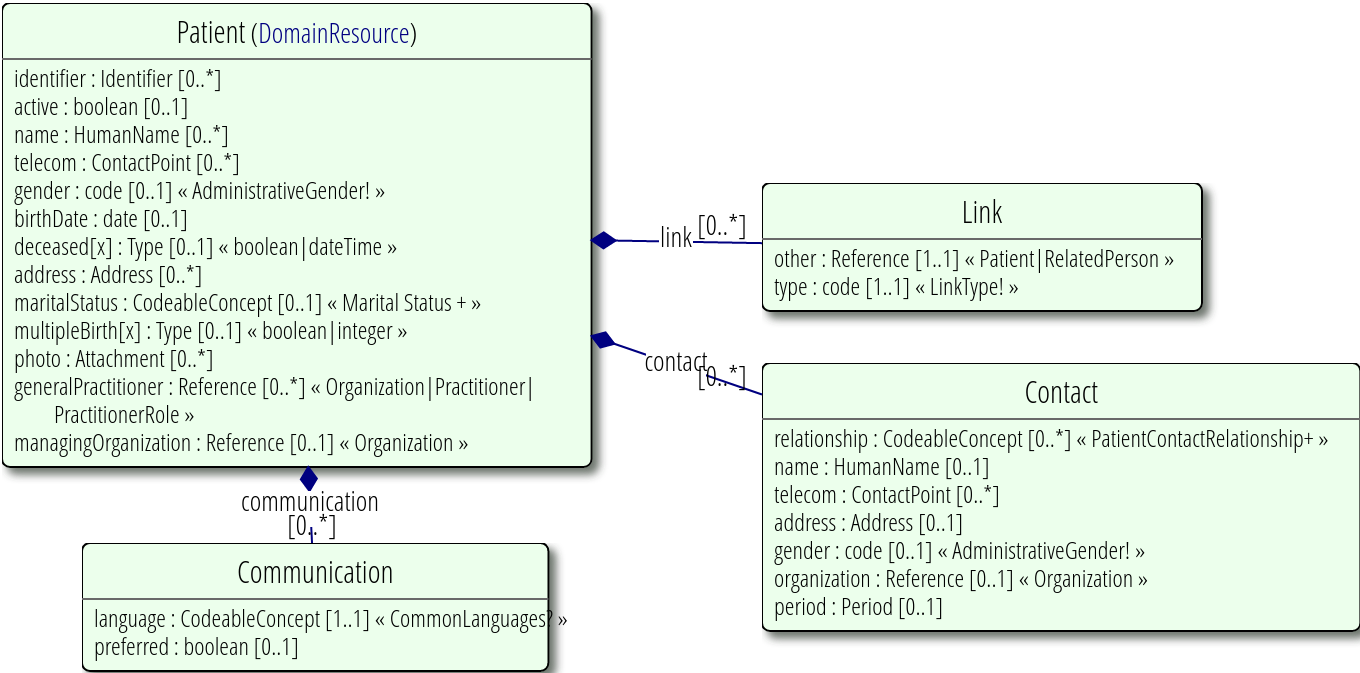
Fuente: FHIR v4.0.1 Patient
El siguiente ejemplo es un recurso de informe diagnóstico, que incluye su identificador, estado, categoría, paciente de referencia, fecha, médico, observaciones, conclusión, documentos adjuntos, etcétera.
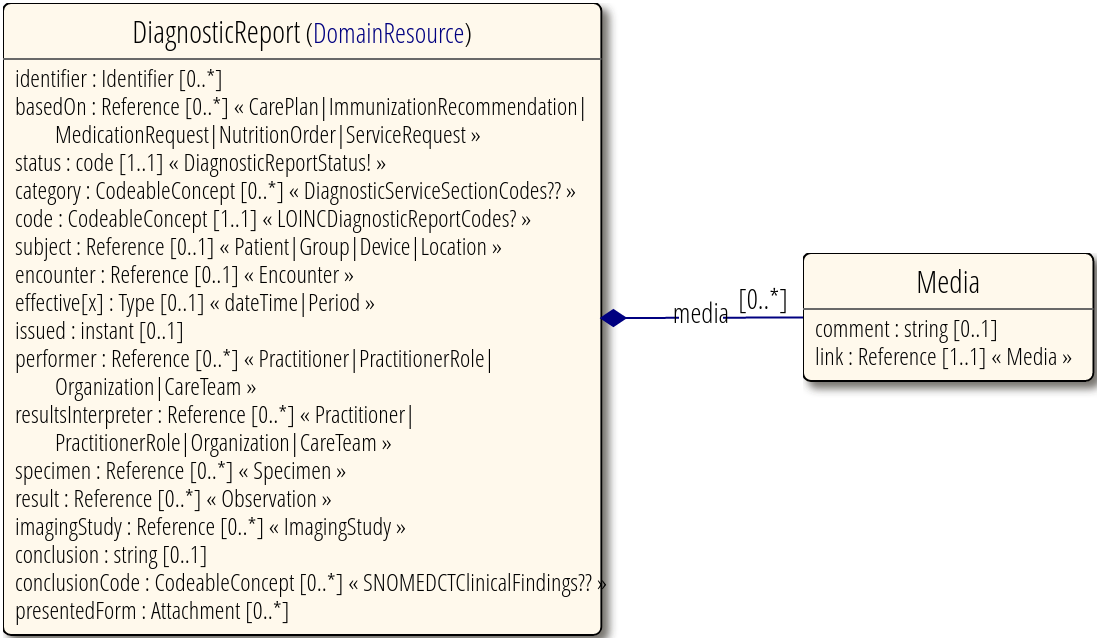
Fuente: FHIR v4.0.1 DiagnosticReport
El modelo no se limita a definir tipos de datos, sino que va más allá. Se define también la extensibilidad de los recursos, y como ampliarlos para datos adicionales que necesitemos y que no estaban previstos inicialmente. Además existen otras definiciones más amplias en el modelo de datos. Por ejemplo, podemos agrupar múltiples recursos en una agrupación denominada bundle. O crear un profile que defina un caso de uso, y englobe tanto los tipos de recurso necesarios para ese caso de uso como las relaciones entre sus recursos.
5. API de intercambio FHIR
La API está basada en tecnologías web actuales como HTTP y el protocolo RESTful, pudiendo utilizar formatos XML, JSON o RDF para la representación de datos. De manera general, una URI tendría el formato:
VERB [base]/[type]/[id] {?_format=[mime-type]}
dónde se distingue la dirección del servidor, el tipo de recurso, y su identificador.
Las principales interacciones con la API FHIR utilizarán los métodos HTTP habituales:
-
POST: Creación de recurso
-
PUT: Modificación de recurso
-
PATCH: Modificación parcial de un recurso
-
GET: Lectura de un recurso
-
DELETE: Eliminación de un recurso
En el siguiente diagrama vemos el ejemplo de una petición al servidor:
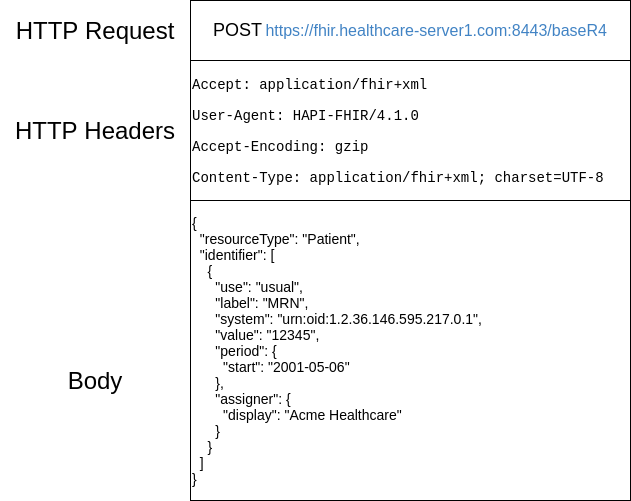
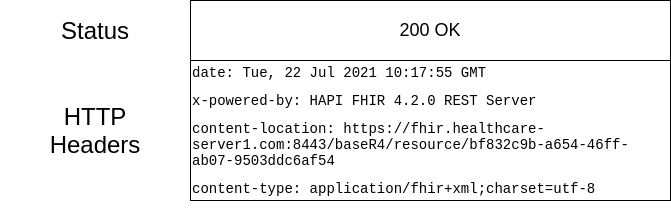
Y la respuesta del servidor:
6. Red Hat Fuse y el componente Apache Camel FHIR
En el mundo real, existen multitud de aplicaciones médicas y dispositivos que no utilizan el estándar FHIR. Los orígenes o destinos de datos de aplicaciones existentes pueden ser diversos:
-
Dispositivos de medición.
-
Datos en bases de datos relacionales.
-
Servicios web en formato propietario.
-
Sistemas de proceso por lotes basados en archivos.
-
Apis rest (no compatibles con FHIR).
-
Colas de mensajes.
-
Aplicaciones SaaS en la nube.
Si queremos comunicarnos con un servidor FHIR, manteniendo la misma infraestructura y aplicaciones existentes, tenemos por tanto que adaptar los datos y el protocolo de comunicación, para que sean compatibles con la especificación. Una de las mejoras opciones, es realizar una micro integración con Red Hat Fuse. Esta potente y versátil herramienta, de la que hemos hablado anteriormente, nos ayudará en el proceso de automatización de las tareas.
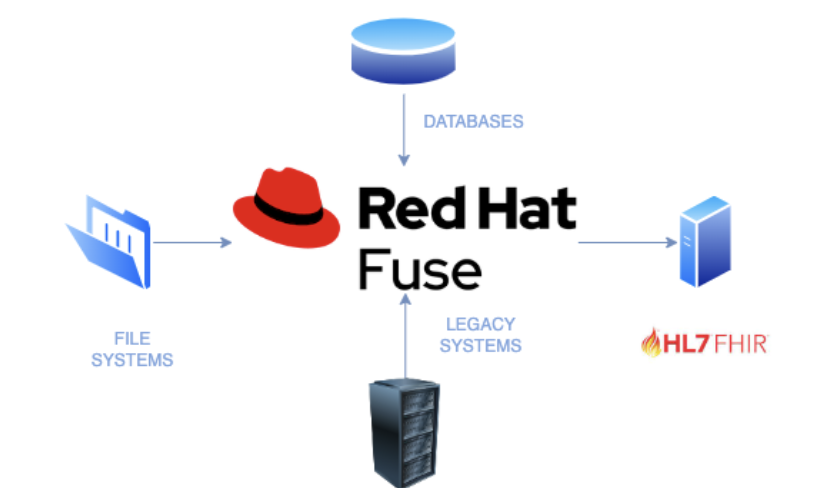
Red Hat Fuse, es la solución para realizar integraciones ágiles de Red Hat. Está basado en un conjunto estable de proyectos Open Source ampliamente utilizados, pero con el respaldo y soporte de una compañía como Red Hat. Teniendo como base Apache Camel para realizar las micro integraciones y la posibilidad de desplegarlo on-premise o en un entorno en la nube a través de Red Hat OpenShift.
6.1 Librería HAPI FHIR
Existen distintas aplicaciones comerciales en el ámbito clínico que soportan FHIR de manera nativa, pero si necesitamos una solución custom que se adapte a nuestras aplicaciones, podemos utilizar una librería especializada. HAPI FHIR es una librería Java para Clientes y Servidores que implementa la especificación HL7 FHIR, de código abierto y disponible bajo licencia Apache Software License 2.0.
HAPI FHIR define un modelo de clase para cada recurso y tipo de datos definido en la especificación FHIR, que a su vez podemos codificar en XML o JSON, para su intercambio a través de las APIs REST. El código fuente puede obtenerse de https://github.com/jamesagnew/hapi-fhir
Los módulos en los que se divide esta librería son:
-
Core: Librería core del framework
-
Structures: Modelos de datos
-
Client Framework: Cliente HTTP, incluyendo una versión para Android
-
Server: Servidor compatible con la especificación FHIR
-
Validation: Validación de recursos contra FHIR Profiles
Podemos ver un ejemplo sencillo del módulo Structures, en el que vemos como se crearía un nuevo paciente con un identificador, género, nombre y apellidos:
Patient patient = new Patient();
patient.setId(IdType.newRandomUuid());
patient.setGender(Enumerations.AdministrativeGender.MALE);
patient.addName()
.setFamily("Connor")
.addGiven("John");
6.2 Apache Camel FHIR
El componente Camel FHIR encapsula las librerías de cliente y servidor HAPI FHIR, comentadas anteriormente, en el framework de Apache Camel, soportando tanto su modelo de datos como el protocolo de comunicación. Su documentación está disponible en:
https://camel.apache.org/components/latest/fhir-component.html
Si utilizamos como opción de despliegue Spring Boot, podemos utilizar una de las librerías que permiten la autoconfiguración de dichos componentes. Para ello hay que introducir la librería.
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-fhir-starter</artifactId>
</dependency>
Dentro de nuestros proyectos podremos utilizar tanto el modelo de datos a través de la librería HAPI FHIR, como gestionar las comunicaciones entre clientes y servidores FHIR.
El componente FHIR se configura utilizando la siguiente sintaxis como endpoint cuando procedamos a transmitir los datos:
fhir://endpoint-prefix/endpoint?[options]
Donde endpoint-prefix corresponde a una de las operaciones posibles:
-
capabilities: Consulta funcionalidad completa del servidor, i.e. operaciones y recursos soportados
-
create: Crea un nuevo recurso en el servidor
-
delete: Elimina un recurso en el servidor
-
history: Consulta versiones y cambios en un recurso
-
load-page: Carga un bundle de recursos previo/siguiente en base a un conjunto paginado
-
meta: Añade, modifica o elimina metadatos de un recurso
-
operation: Permite extender el API con nuevas operaciones
-
patch: Modifica un recurso en el servidor
-
read: Lee un recurso en el servidor
-
search: Busca recursos que coincidan con los criterios de búsqueda
-
transaction: Envía una colección de recursos de manera unitaria
-
update: Actualiza un recurso en el servidor
-
validate: Valida si un recurso es conforme a la especificación
Además de indicarle la operación, existen múltiples parámetros que varían en función de la operación a realizar, y que nos permitirán ajustar ciertos aspectos de la misma.
6.3 Ejemplo de implementación mediante Camel FHIR
Supongamos que tenemos un fichero en formato CSV que contiene una lista de registros clínicos. Necesitamos leer esos registros y enviarlos a un servidor FHIR. Para ello, de manera general seguiremos los siguientes pasos:
-
Cargar el fichero
-
Leer el contenido en formato CSV
-
Convertir a un formato FHIR Bundle
-
Enviar el bundle al servidor
Como estamos cargando múltiples registros a la vez, podemos utilizar la operación transaction, que nos permite enviar un bundle o colección de registros.
BindyCsvDataFormat bindy = new BindyCsvDataFormat(Record.class);
@Override
public void configure() throws Exception {
from("file://{{dir.in}}?noop=true").filter(simple("${file:name.ext} == 'csv'")).id("readingCsvFiles")
.log("Converting ${in.headers.CamelFileName}").unmarshal(bindy).log("body ${body}").process(new BundleProcessor())
.log("Sending HL7 FHIR Bundle")
.to("fhir://transaction/withBundle?inBody=bundle&serverUrl={{fhirUrl}}&fhirVersion={{fhirVersion}}&validationMode=NEVER").log("CSV imported")
.end();
}
Así podemos ver un ejemplo de la utilización de FHIR con Red Hat Fuse y Apache Camel, indicada por el protocolo fhir://
Código fuente del proyecto:






