Dans cet article, nous expliquerons ce qu’est HL7, ainsi que ce qu’est HL7 FHIR pour l’échange d’informations cliniques et l’intégration avec Apache Camel.
Nous suivrons l’indice suivant:
|
1. Qu’est-ce que HL7?
Health Level Seven International (HL7) est une organisation à but non lucratif fondée en 1987 dans le but de développer un cadre complet de normes pour l’échange, l’intégration, le partage et l’obtention d’informations cliniques au format électronique pour une utilisation dans la pratique clinique et dans la gestion , la prestation et l’évaluation des services de santé. Cette organisation est composée de plus de 1600 membres dans plus de 50 pays, représentant des prestataires de services de santé, des gouvernements, des assureurs, des sociétés pharmaceutiques, des fabricants et des sociétés de conseil.
Son objectif est de faciliter l’interopérabilité des données cliniques au niveau mondial.
2. Qu’est-ce que HL7 FHIR?
HL7 Fast Healthcare Interoperability Resources (FHIR) est une norme d’interopérabilité visant à faciliter l’échange d’informations cliniques entre les prestataires de soins de santé, les patients, les soignants, les assureurs, les chercheurs et toute autre partie impliquée dans l’écosystème de la santé.
FHIR définit deux aspects:
- Un modèle de données sur les ressources de santé
- Une API pour l’échange d’informations
2.1 Évolution du FHIR
FHIR es la evolución de varios estándares producidos por la organización HL7 a lo largo de décadas, partiendo de versiones anteriores como HL7 version 2.x and HL7 version 3.x. Desde 2011 se han ido publicando distintas propuestas, siendo la Release 4 la última versión estable.
- Octobre 2019 : FHIR R4, Première version normative
- Mars 2017 : FHIR R3, Standards for Trial Use (STU)
- Octobre 2015 : FHIR R2 DSTU, Draft Standard for Trial Use (DSTU) (ébauche)
- Février 2014 : FHIR R1 DSTU, Draft Standard for Trial Use (DSTU) (ébauche)
- Août 2011 : Ressources pour les soins de santé (RFH) (version initiale)
2.2 Avantages de HL7 FHIR
Les principaux avantages de l’utilisation de FHIR sont les suivants:
- Il permet de faciliter l’interopérabilité entre des systèmes hétérogènes, des systèmes existants, à de multiples types d’appareils tels que les ordinateurs, tablettes, smartphones, dispositifs médicaux, etc., ainsi qu’entre différentes applications, et facilite l’intégration de nouvelles applications médicales avec les systèmes existants.
- Il constitue une alternative aux systèmes basés sur des documents, permettant un plus grand degré de détail en pouvant exposer des éléments en tant que services. Par exemple, des éléments de base tels que les patients, les admissions, les analyses, les diagnostics, les médicaments, peuvent être consultés et manipulés individuellement via leur propre URL.
- La standardisation et la granularité du modèle de données permettent d’accélérer son traitement automatique, sans avoir recours à des techniques de transformation ou de pré-traitement.
- Il est facilement intégrable avec les applications actuelles car son API est basée sur les technologies REST.
- Il existe des implémentations open source pour différents langages tels que Java, .NET, Ruby, Python, Delphi, Swift, PHP, …
3. Cas d’utilisation FHIR
L’échange d’informations cliniques entre différentes parties peut conduire à des cas d’usage comme par exemple:
- Alerte d’interaction médicamenteuse: le système peut alerter lorsque des médicaments sont prescrits en même temps qui peuvent interagir les uns avec les autres de manière négative pour la santé du patient.
- Réduction des temps d’attente: L’analyse des données issues des soins d’urgence et des admissions hospitalières peut permettre un meilleur dimensionnement et une optimisation des ressources pour réduire les temps d’attente.
- Surveillance épidémiologique: les hôpitaux peuvent publier des statistiques d’infection pour leurs patients afin qu’elles puissent être exploitées par les chercheurs et les agences de santé publique.
- Télémédecine: Transmission des appareils de mesure (tensiomètres, thermomètres, glucomètres, spiromètres, …) du domicile du patient au service de santé pour surveillance et analyse.
4. Modèle de données FHIR
Les données fondamentales dans FHIR sont ce qu’on appelle la ressource. Des exemples de ressources peuvent être : admission, patient, antécédents, médicaments, plan de réadaptation, sortie, …
Nous pouvons définir une ressource comme une entité qui :
- Il possède une identité unique (emplacement URL) attribuée sur le serveur.
- Il appartient à un type de ressource parmi ceux définis par la spécification FHIR.
- Il contient un ensemble de données structurées, selon le type de ressource.
- Il a une version qui change si le contenu de la ressource est modifié.
Chaque ressource est constituée d’une structure de données qui peut être de type primitif ou complexe, ou des références à d’autres ressources.
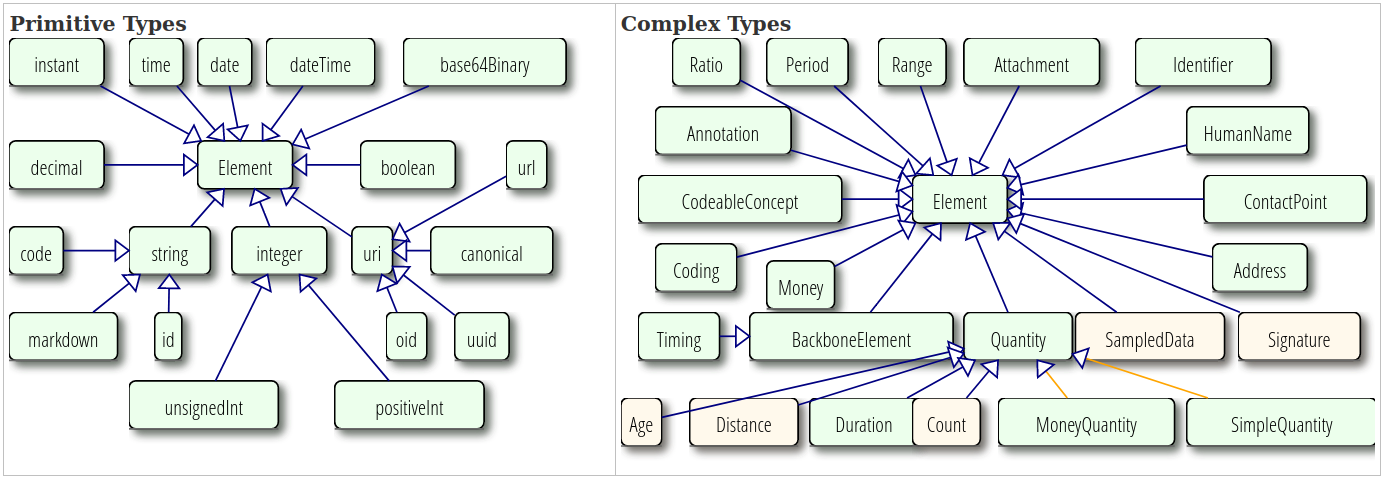
Source: FHIR v4.0.1 Datatypes Definitions
Dans le schéma suivant, nous voyons un exemple de ressource patient, qui se compose d’un identifiant, d’une date de naissance, d’un état civil, de personnes de contact, d’un médecin, etc
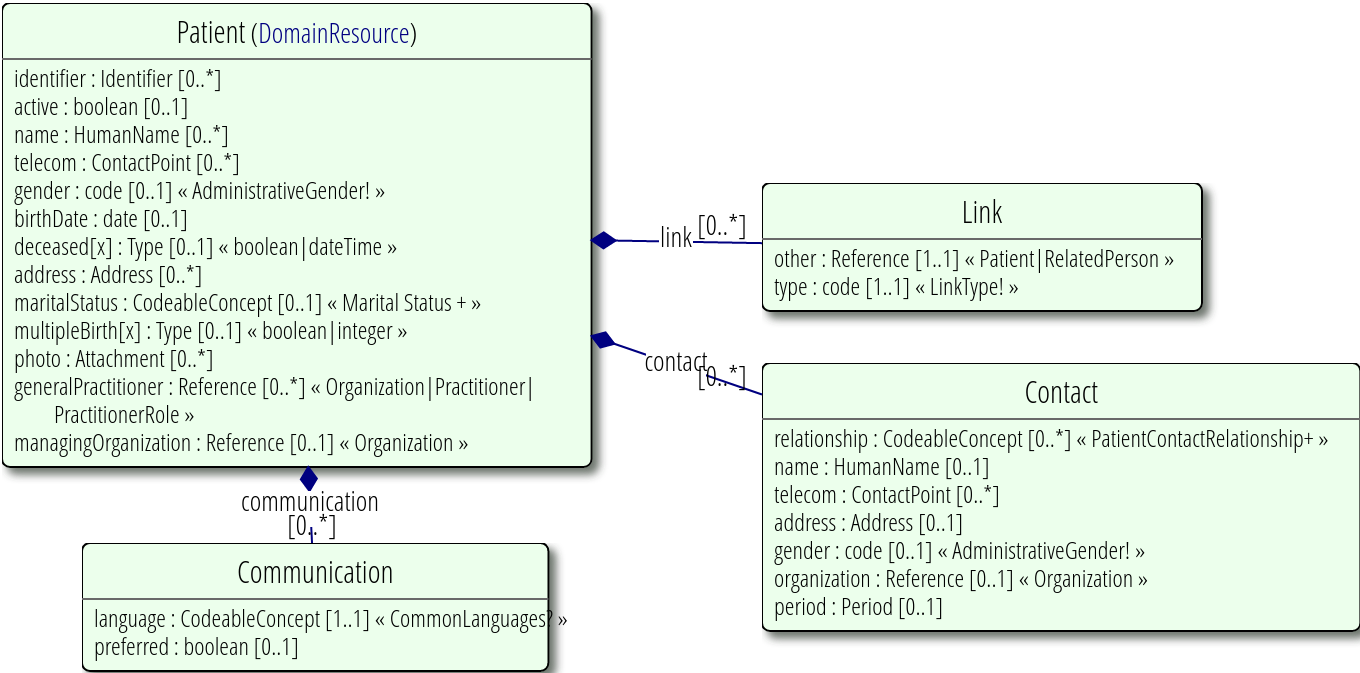
Source: FHIR v4.0.1 Patient
L’exemple suivant est une ressource de rapport de diagnostic, qui comprend son identifiant, son état, sa catégorie, son patient référé, sa date, son médecin, ses observations, sa conclusion, ses pièces jointes, etc.
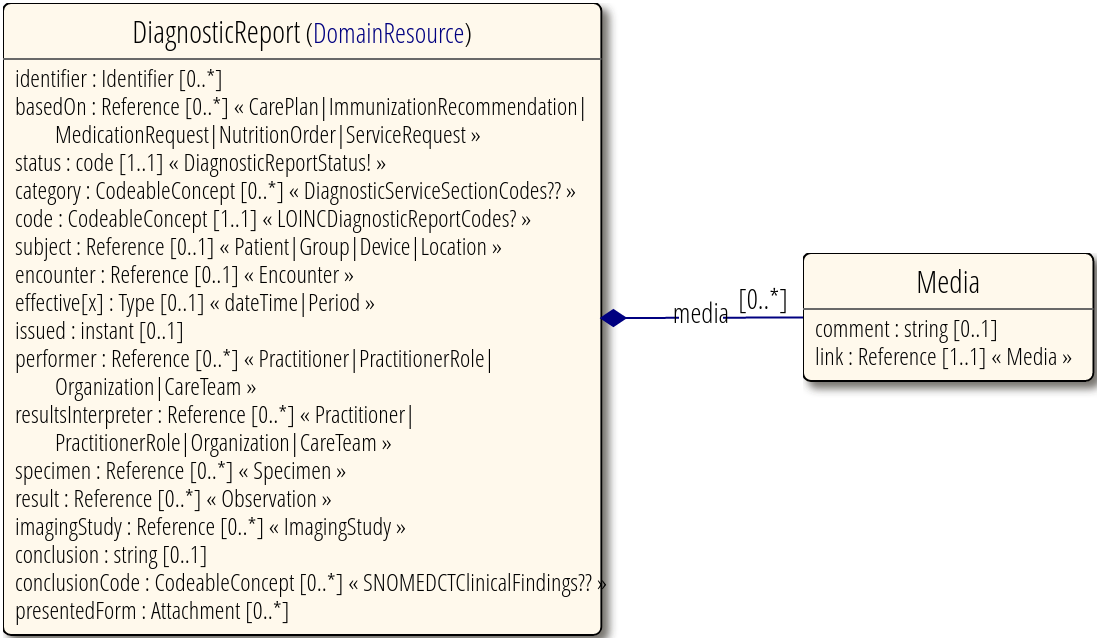
Source: FHIR v4.0.1 DiagnosticReport
Le modèle ne se limite pas à définir des types de données, mais va plus loin. L’extensibilité des ressources est également définie, et comment les étendre pour des données supplémentaires dont nous avons besoin et qui n’étaient pas initialement prévues. En outre, il existe d’autres définitions plus larges dans le modèle de données. Par exemple, nous pouvons regrouper plusieurs ressources dans un regroupement appelé bundle. Ou créez un profil qui définit un cas d’utilisation et englobe à la fois les types de ressources requis pour ce cas d’utilisation et les relations entre ses ressources.
5. API d’échange FHIR
L’API est basée sur les technologies Web actuelles telles que HTTP et le protocole RESTful, pouvant utiliser les formats XML, JSON ou RDF pour la représentation des données. En général, un URI aurait le format :
VERB [base]/[type]/[id] {?_format=[mime-type]}
où l’adresse du serveur, le type de ressource, et son identifiant sont distingués.
Les principales interactions avec l’API FHIR utiliseront les méthodes HTTP habituelles :
- POST: Création de ressources
- PUT: Modification des ressources
- PATCH: Modification partielle d’une ressource
- GET: Lire une ressource
- DELETE: Supprimer une ressource
Élimination d’un Dans le diagramme suivant, nous voyons un exemple d’une requête au serveur:
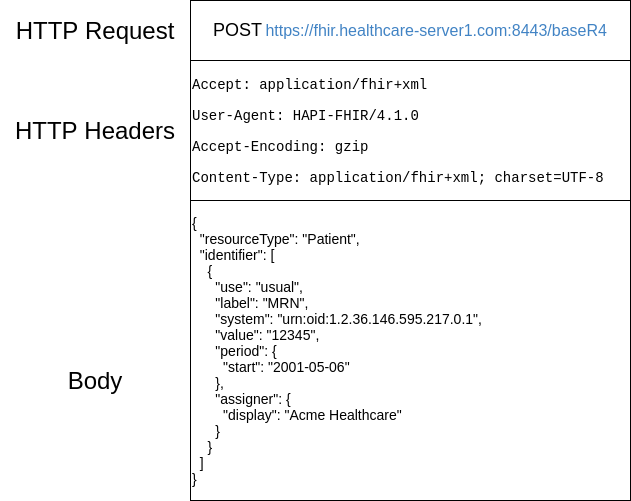
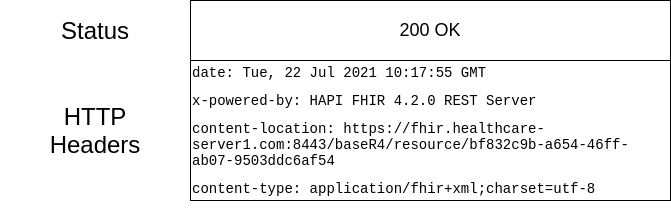
Et la réponse du serveur:
6. Apache Camel et le composant FHIR
Dans le monde réel, il existe de nombreuses applications et dispositifs médicaux qui n’utilisent pas la norme FHIR. Les sources ou destinations des données applicatives existantes peuvent être diverses:
- Instruments de mesure.
- Données dans les bases de données relationnelles.
- Services Web au format propriétaire.
- Systèmes de traitement par lots basés sur des fichiers.
- APIs REST(non compatible avec FHIR).
- Files d’attente de messages.
- Applications SaaS dans le cloud.
Si l’on veut communiquer avec un serveur FHIR, en conservant la même infrastructure et les mêmes applications existantes, il faut donc adapter les données et le protocole de communication, afin qu’ils soient compatibles avec le cahier des charges. Une option consiste à utiliser un outil d’intégration comme Apache Camel, qui automatise ce processus.
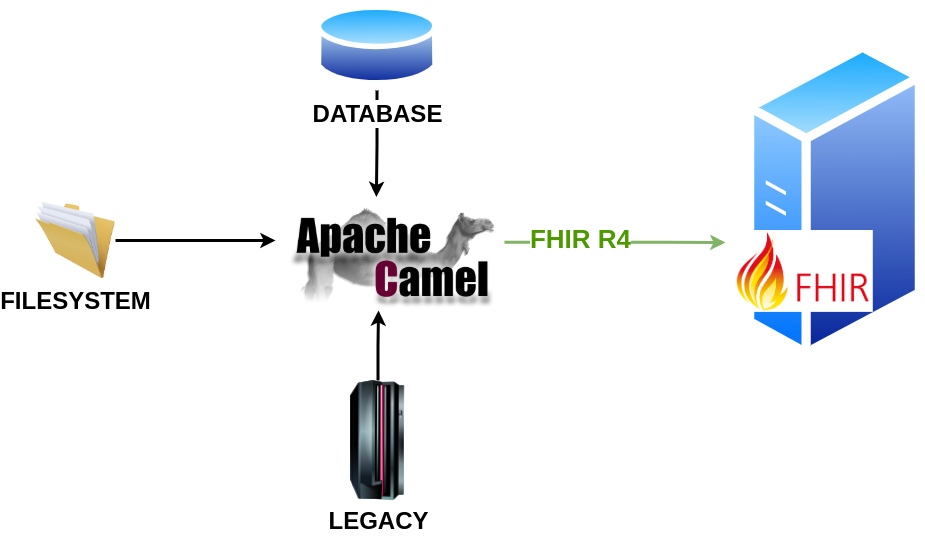
Apache Camel est un framework d’intégration open source qui nous permet d’intégrer facilement divers systèmes d’information qui produisent ou consomment divers types de données et de protocoles. Il existe des centaines de composants prédéfinis que nous pouvons utiliser dans nos projets qui nous aideront à intégrer facilement différents producteurs et consommateurs de données.
6.1 Librairie HAPI FHIR
Il existe différentes applications commerciales dans le domaine clinique qui prennent en charge nativement FHIR, mais si nous avons besoin d’une solution personnalisée qui s’adapte à nos applications, nous pouvons utiliser une librairie spécialisée. HAPI FHIR est une librairie Java pour clients et serveurs qui implémente la spécification HL7 FHIR, open source et disponible sous la licence logicielle Apache 2.0.
HAPI FHIR définit un modèle de classe pour chaque ressource et type de données défini dans la spécification FHIR, qui à son tour peut être encodé en XML ou JSON, pour un échange via des APIs REST. Le code source peut être obtenu sur https://github.com/jamesagnew/hapi-fhir.
Les modules dans lesquels cette librairie est divisée sont:
- Core: Librairie de base du framework
- Structures: Modèles de données
- Client Framework: Cliente HTTP, incluyendo una versión para Android
- Server: Serveur conforme aux spécifications FHIR
- Validation: Validation des ressources par rapport aux profils FHIR
Nous pouvons voir un exemple simple du module Structures, dans lequel nous voyons comment un nouveau patient serait créé avec un identifiant, un sexe, un nom et un prénom :
Patient patient = new Patient();
patient.setId(IdType.newRandomUuid());
patient.setGender(Enumerations.AdministrativeGender.MALE);
patient.addName()
.setFamily("Connor")
.addGiven("John");
6.2 Camel FHIR
Le composant Camel FHIR encapsule les librairies client et serveur HAPI FHIR, décrites ci-dessus, dans le framework Apache Camel, prenant en charge à la fois son modèle de données et le protocole de communication. Sa documentation est disponible sur :
https://camel.apache.org/components/latest/fhir-component.html
Pour commencer à l’utiliser, il suffit d’ajouter sa dépendance à notre projet Apache Camel :
<dependency>
<groupId>org.apache.camel</groupId>
<artifactId>camel-fhir</artifactId>
<version>${camel-version}</version>
</dependency>
Au sein de nos projets nous pourrons à la fois utiliser le modèle de données via la Librairie HAPI FHIR, et gérer les communications entre les clients et les serveurs FHIR.
Le composant FHIR est configuré à l’aide de la syntaxe suivante comme point de terminaison lorsque nous procédons à la transmission des données:
fhir://endpoint-prefix/endpoint?[options]
Où l’endpoint-prefix correspond à l’une des opérations possibles:
- capabilities: Voir toutes les fonctionnalités du serveur, c’est-à-dire opérations et ressources prises en charge
- create: Créer une nouvelle ressource sur le serveur
- delete: Supprimer une ressource sur le serveur
- history: Vérifier les versions et les modifications d’une ressource
- load-page: Charge un ensemble de ressources précédent/suivant en fonction d’un ensemble paginé
- meta: Ajouter, modifier ou supprimer des métadonnées pour une ressource
- operation: Permet d’étendre l’API avec de nouvelles opérations
- patch: Modifier une ressource sur le serveur
- read: Lire une ressource sur le serveur
- search: Trouvez des ressources qui correspondent à vos critères de recherche
- transaction: Envoyer une collection de ressources de manière unitaire
- update: Mettre à jour une ressource sur le serveur
- validate: Valider si une ressource est conforme au cahier des charges
En plus d’indiquer l’opération, il existe de multiples paramètres qui varient en fonction de l’opération à effectuer, et qui vont nous permettre d’en ajuster certains aspects.
6.3 Exemple d’implémentation avec Camel FHIR
Supposons que nous ayons un fichier au format CSV contenant une liste de dossiers cliniques. Nous devons lire ces journaux et les envoyer à un serveur FHIR. Pour ce faire, en général, nous suivrons les étapes suivantes:
- Télécharger le fichier
- Lire le contenu au format CSV
- Convertir en un format de paquet FHIR
- Envoyer le bundle au serveur
Comme nous chargeons plusieurs enregistrements en même temps, nous pouvons utiliser l’opération de transaction, qui nous permet d’envoyer un bundle ou une collection d’enregistrements.
@Component
public class CSV2FHIR extends RouteBuilder {
@Override
public void configure() throws Exception {
from("file:{{directoryName}}?fileName={{fileName}}&noop=true")
.log("Converting {{fileName}}")
.unmarshal().csv()
.convertBodyTo(Bundle.class)
.log("Sending HL7 FHIR Bundle")
.to("fhir://transaction/withBundle?inBody=bundle&serverUrl={{url}}&fhirVersion={{version}}")
.log("CSV imported");
}
}
On peut donc voir un exemple d’utilisation de FHIR avec Camel, indiqué par le fhir : // protocole. Grâce à ce préfixe, les données sont envoyées automatiquement via le composant FHIR, qui gère la communication et l’envoi du bundle vers le serveur défini par le paramètre serverUrl, ainsi que la réception de la réponse.






